fdacluster
An R package for joint clustering and alignment of functional data
L. Bellanger, A. Stamm 
Department of Mathematics Jean Leray, UMR CNRS 6629, Nantes University, France
2023-06-22
Functional data - Derivatives
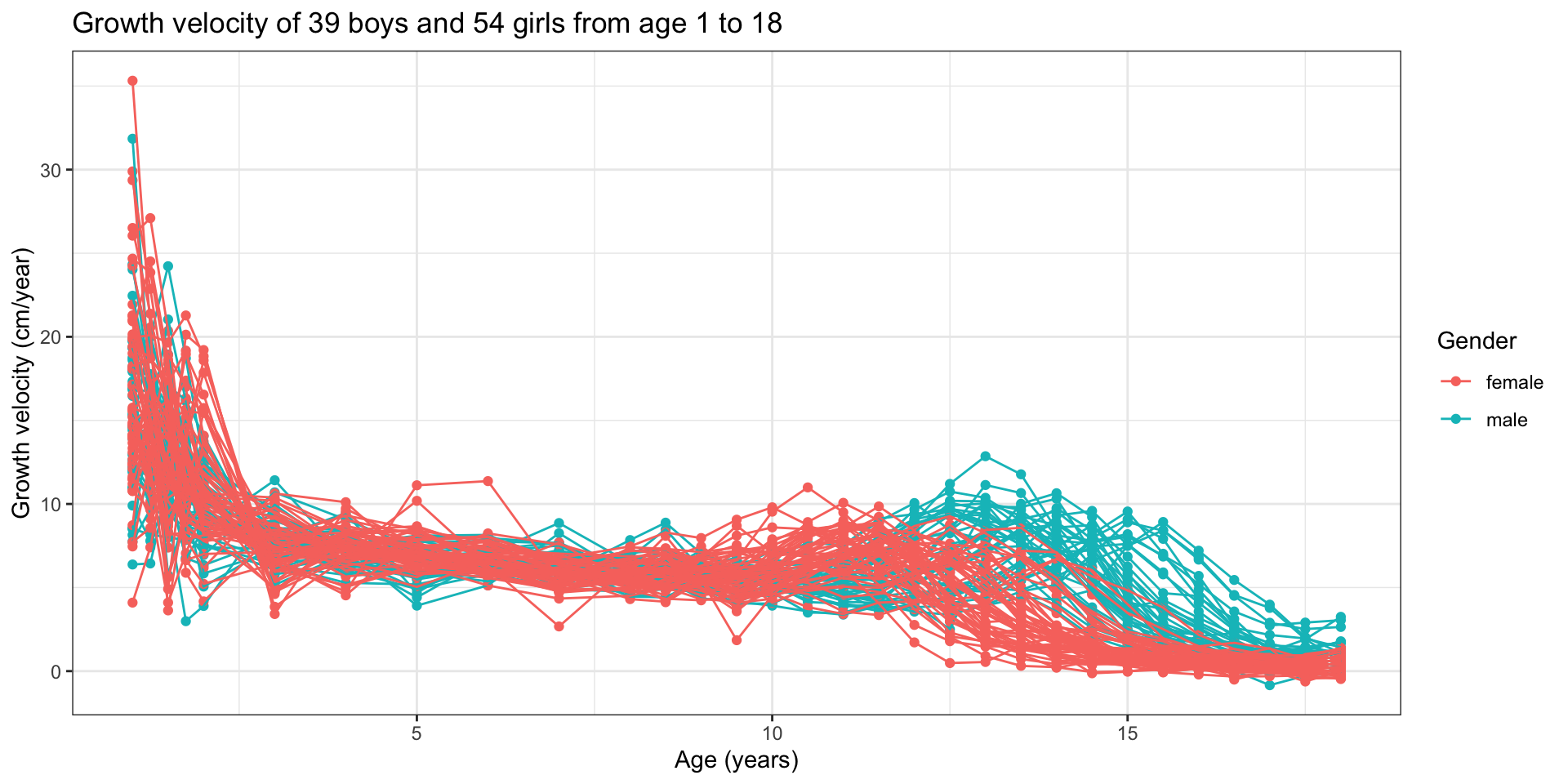
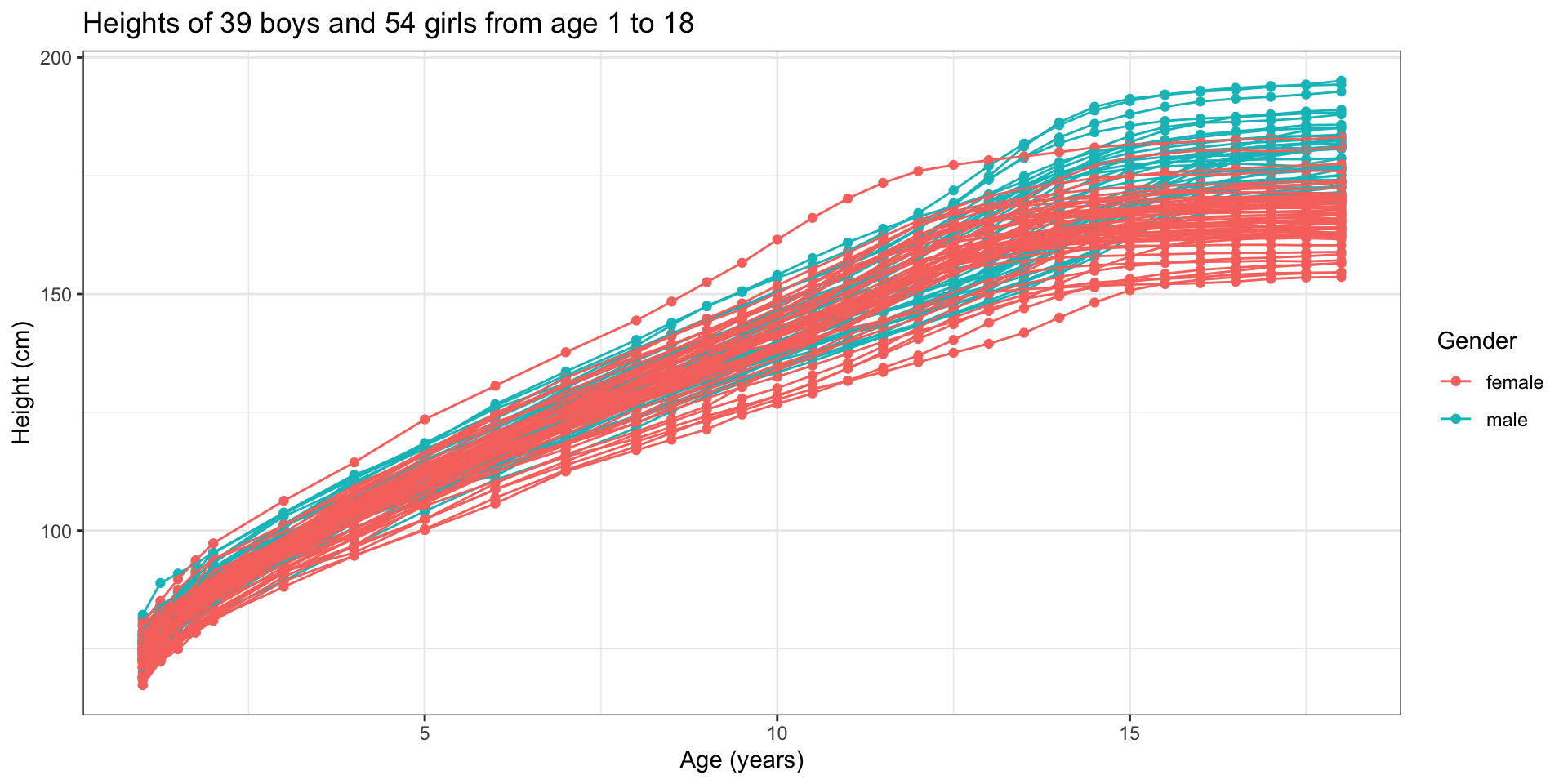
What if we did not know gender membership?
- Common peak of growth velocity shortly after birth
- Another smaller peak at puberty occurring:
- At different ages for girls and for boys;
- At different ages for each individual.
Functional data - A simpler example
Data source: Sangalli et al. (2010).
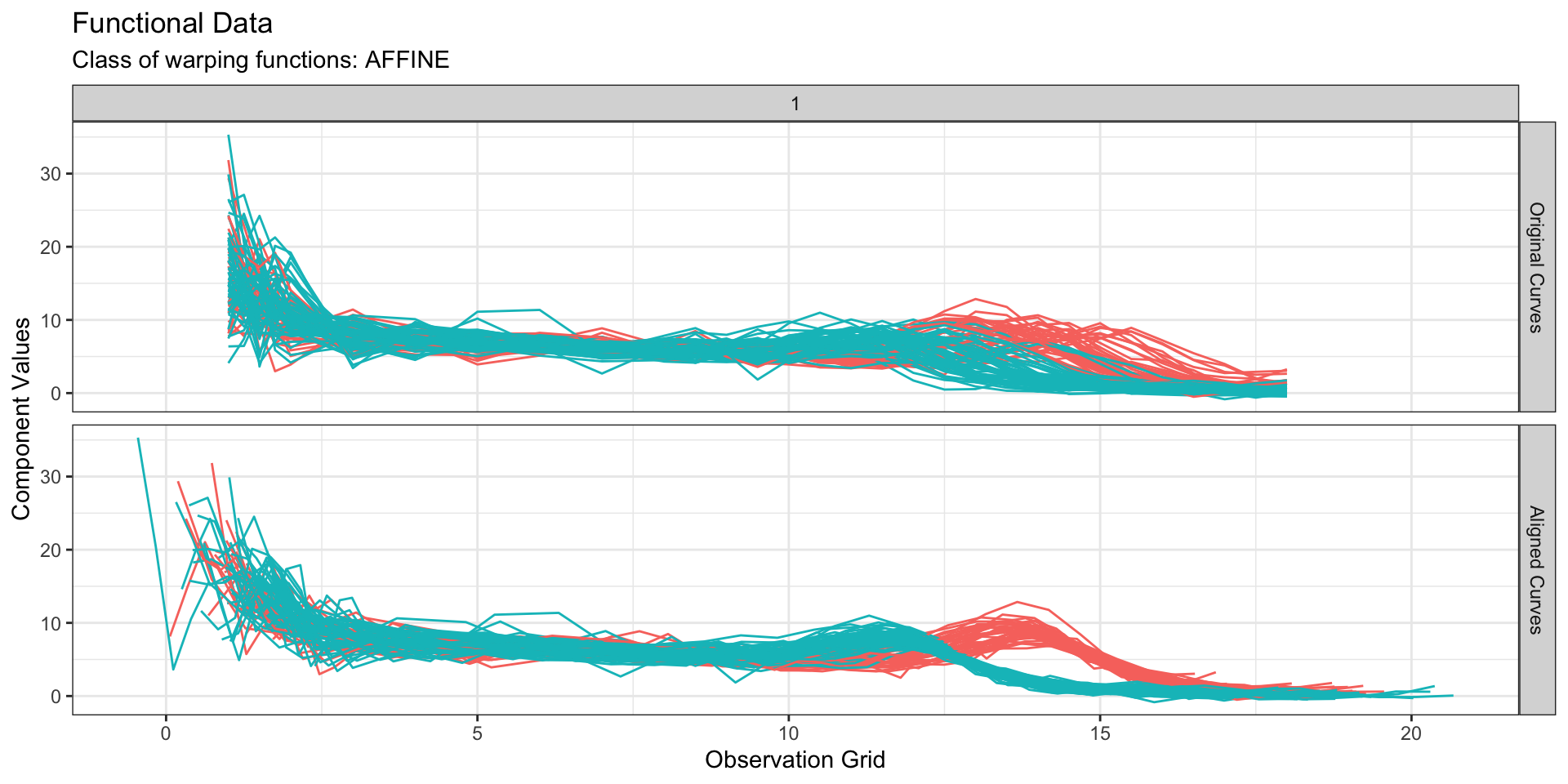
Functional data - Clustering
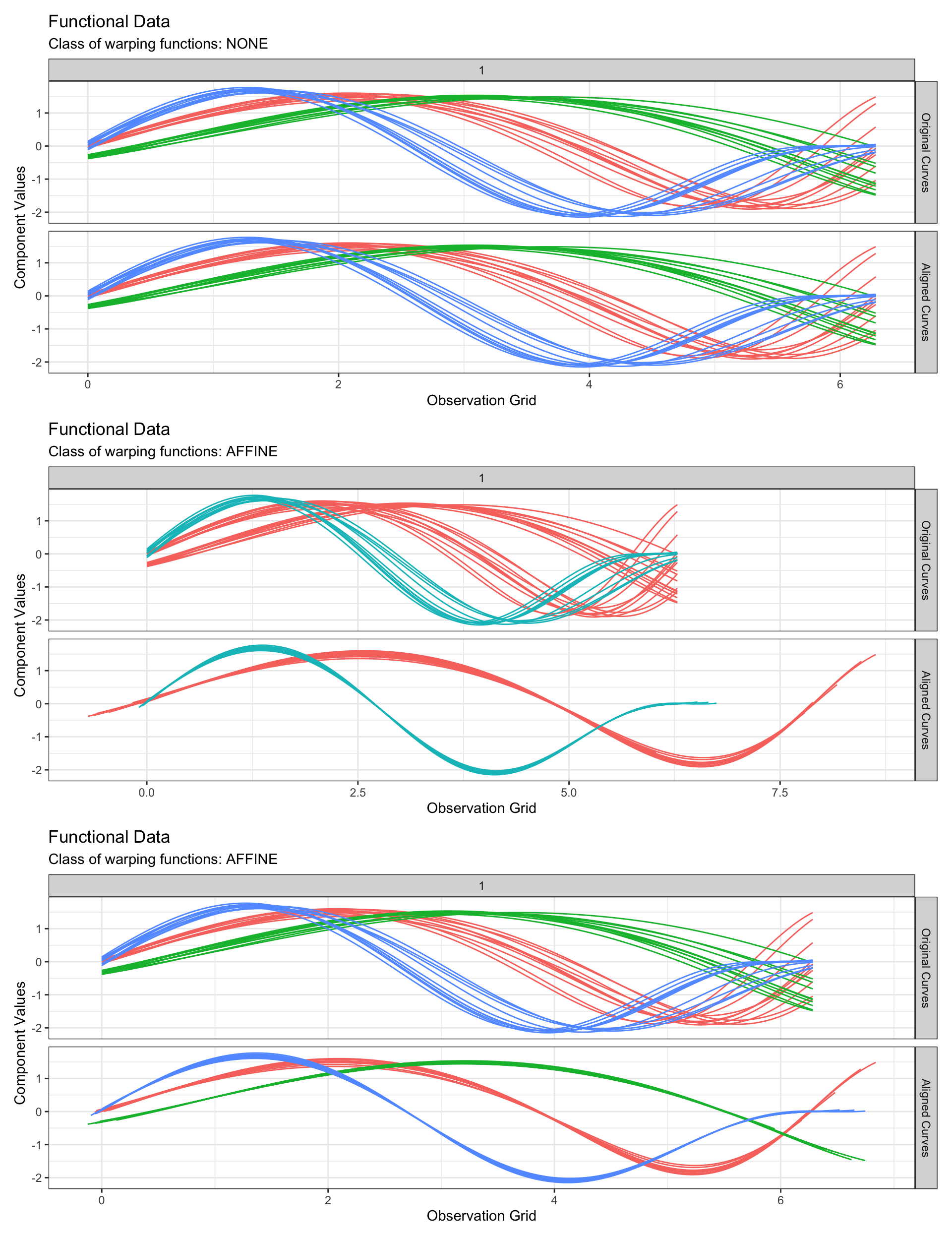
Solution 1: \[ \begin{cases} d_A^2(f, g) = d^2(f, g) \\ d_C^2(f, g) = d_A^2(f, g) \end{cases} \]
Solutions 2 & 3: \[ \begin{cases} d_A^2(f, g) = \min_{h \in W} d^2(f \circ h, g) \\ d_C^2(f, g) = d_A^2(f, g) \end{cases} \]
\[ \begin{cases} d_A^2(f, g) = \min_{h \in W} d^2(f \circ h, g) \\ d_C^2(f, g) = \int_{\mathcal{D}} \left[ h^\star(t) - t \right]^2 dt \\ \end{cases} \] with \(h^\star(t) = \arg \min_{h \in W} d^2(f \circ h, g)\).
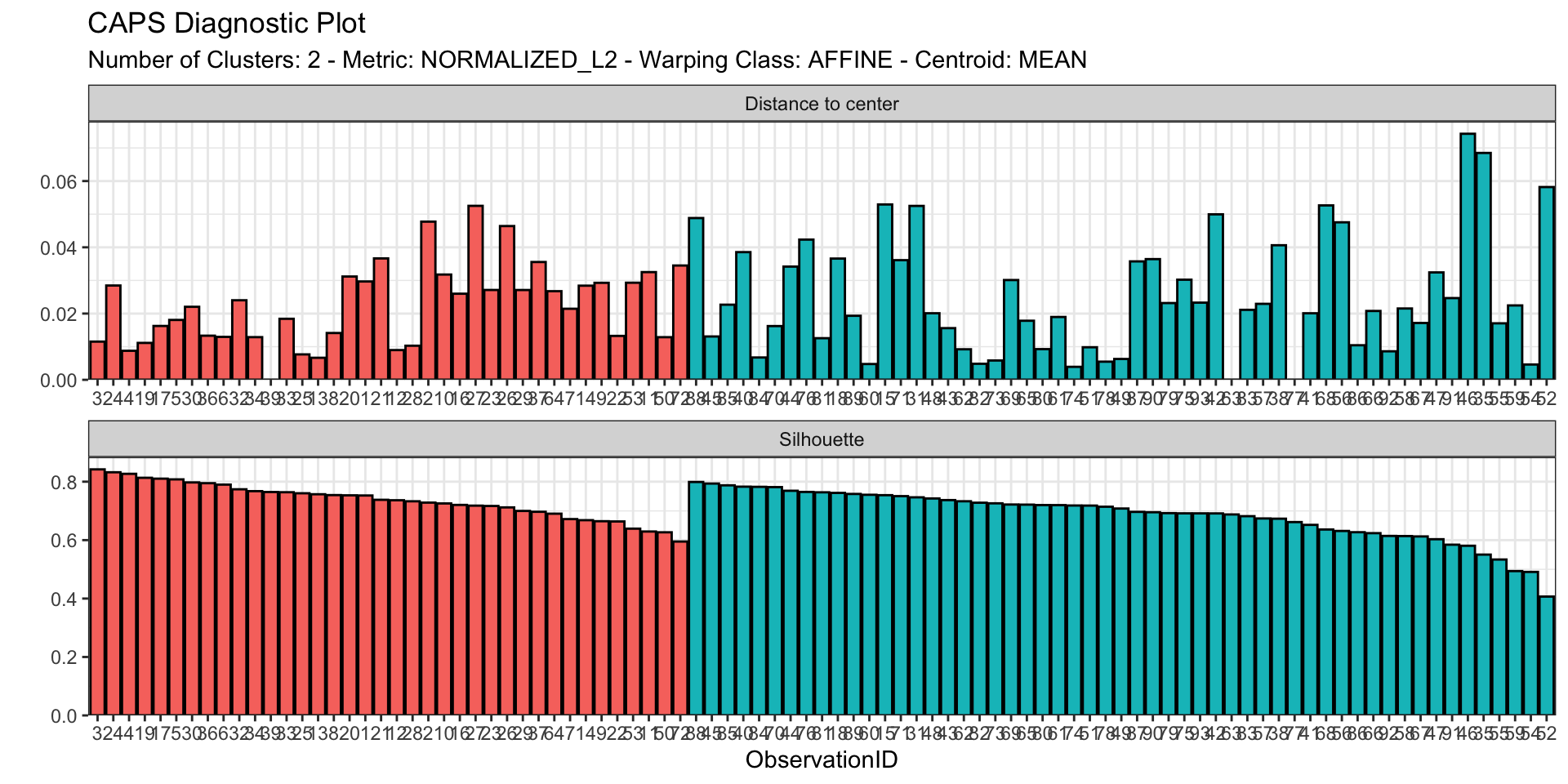
The caps class
List of 14
$ original_curves : num [1:93, 1, 1:31] 12.44 18.13 12.02 16.92 8.51 ...
$ original_grids : num [1:93, 1:31] 1 1 1 1 1 1 1 1 1 1 ...
$ aligned_grids : num [1:93, 1:31] 1.536 1.294 1.862 0.938 2.29 ...
$ center_curves : num [1:2, 1, 1:31] 19.7 17.7 16.1 15.4 12.5 ...
$ center_grids : num [1:2, 1:31] 0.302 0.296 0.937 0.956 1.572 ...
$ n_clusters : num 2
$ memberships : Named int [1:93] 1 1 1 1 1 1 1 1 1 1 ...
..- attr(*, "names")= chr [1:93] "1" "2" "3" "4" ...
$ distances_to_center: num [1:93] 0.02969 0.04775 0.01153 0.00876 0.01807 ...
$ silhouettes : num [1:93] 0.753 0.728 0.842 0.827 0.808 ...
$ amplitude_variation: num 0.0582
$ total_variation : num 0.135
$ n_iterations : num 0
$ call_name : chr "fdahclust"
$ call_args :List of 20
..$ x : symbol x
..$ y : language t(y1)
..$ n_clusters : num 2
..$ is_domain_interval : logi FALSE
..$ transformation : chr "identity"
..$ warping_class : chr "affine"
..$ centroid_type : chr "mean"
..$ metric : chr "normalized_l2"
..$ cluster_on_phase : logi TRUE
..$ linkage_criterion : chr "complete"
..$ use_verbose : logi FALSE
..$ warping_options : language c(0.15, 0.15)
..$ maximum_number_of_iterations: int 100
..$ number_of_threads : int 1
..$ parallel_method : int 0
..$ distance_relative_tolerance : num 0.001
..$ use_fence : logi FALSE
..$ check_total_dissimilarity : logi TRUE
..$ compute_overall_center : logi FALSE
..$ centroid_extra : num 0
- attr(*, "class")= chr [1:2] "caps" "list"